
Announcing lintspec
Contents
- TL;DR
- Introduction
- Natspec-smells
- A (Long) Weekend Project
- Features
- Benchmark
- Run It in CI
- What’s Next
- Updated 2025-03-14
TL;DR
lintspec is a command-line utility (linter) that checks the completeness and
validity of NatSpec doc-comments in Solidity code. It is focused on speed and ergonomics and aims to improve the user
experience over existing solutions. Benchmarks show that it can be as much as 200 times faster than natspec-smells. A
native GitHub Action allows to easily integrate it with CI.
Install
Via cargo
cargo install lintspecVia cargo-binstall
cargo binstall lintspecVia nix
Depending on your use case, use one of the commands below (on the unstable channel):
nix-env -iA nixpkgs.lintspecnix-shell -p lintspecnix run nixpkgs#lintspecPre-built binaries and install script
Head over to the releases page!
Usage
Usage: lintspec [OPTIONS] [PATH]... [COMMAND]
Commands:
init Create a `.lintspec.toml` config file with default values
help Print this message or the help of the given subcommand(s)
Arguments:
[PATH]... One or more paths to files and folders to analyze
Options:
-e, --exclude <EXCLUDE> Path to a file or folder to exclude (can be used more than once)
-o, --out <OUT> Write output to a file instead of stderr
--inheritdoc Enforce that all public and external items have `@inheritdoc`
--notice-or-dev Do not distinguish between `@notice` and `@dev` when considering "required" validation rules
--notice-ignored <TYPE> Ignore `@notice` for these items (can be used more than once)
--notice-required <TYPE> Enforce `@notice` for these items (can be used more than once)
--notice-forbidden <TYPE> Forbid `@notice` for these items (can be used more than once)
--dev-ignored <TYPE> Ignore `@dev` for these items (can be used more than once)
--dev-required <TYPE> Enforce `@dev` for these items (can be used more than once)
--dev-forbidden <TYPE> Forbid `@dev` for these items (can be used more than once)
--param-ignored <TYPE> Ignore `@param` for these items (can be used more than once)
--param-required <TYPE> Enforce `@param` for these items (can be used more than once)
--param-forbidden <TYPE> Forbid `@param` for these items (can be used more than once)
--return-ignored <TYPE> Ignore `@return` for these items (can be used more than once)
--return-required <TYPE> Enforce `@return` for these items (can be used more than once)
--return-forbidden <TYPE> Forbid `@return` for these items (can be used more than once)
--json Output diagnostics in JSON format
--compact Compact output
--sort Sort the results by file path
-h, --help Print help (see more with '--help')
-V, --version Print versionIntroduction
The Solidity language provides a succinct specification for documentation comments used to provide rich documentation for functions, arguments, return values, and more. These were apparently inspired by Doxygen and look like so (example taken from the official Solidity documentation linked above):
// SPDX-License-Identifier: GPL-3.0
pragma solidity >=0.8.2 < 0.9.0;
/// @title A simulator for trees
/// @author Larry A. Gardner
/// @notice You can use this contract for only the most basic simulation
/// @dev All function calls are currently implemented without side effects
/// @custom:experimental This is an experimental contract.
contract Tree {
/// @notice Calculate tree age in years, rounded up, for live trees
/// @dev The Alexandr N. Tetearing algorithm could increase precision
/// @param rings The number of rings from dendrochronological sample
/// @return Age in years, rounded up for partial years
/// @return Name of the tree
function age(uint256 rings) external virtual pure returns (uint256, string memory) {
return (rings + 1, "tree");
}
/// @notice Returns the amount of leaves the tree has.
/// @dev Returns only a fixed number.
function leaves() external virtual pure returns(uint256) {
return 2;
}
}Toolchains like Foundry (which, by the way, reached v1.0 recently 🎉) can use those comments to automatically generate
Markdown and HTML files for documentating a project’s API.
As such, it’s pretty important to make sure that these comments stay in sync with the actual code, and even more important to ensure that they are present altogether!
Natspec-smells
I’m not the first one to identify this need, and the good folks over at Wonderland did so a while ago, and provide a CLI tool that can be used to validate those comments: natspec-smells.
Having used this tool pretty much since its inception in January 2024, I was always a bit disappointed by its speed
and the fact that it sometimes errors for seemingly unrelated reasons, like it not being able to understand the path to a source file’s
dependencies. Another lacking feature, as of writing this, is the verification of enum NatSpec.
A (Long) Weekend Project
In 2023, the Nomic Foundation, which is well known for having developped the Hardhat
development framework, started working on a new Solidity parser named slang and written in Rust. After playing for a while with their CST implementation (an Abstract Syntax Tree with added context about the original source code where nodes were found) for
various small test linting tools, I felt like I had a pretty good grasp of how to use their tree-walking cursor and
query language.
I started working on a code formatter for Solidity using slang (which is still a work-in-progress) and learned a lot
about how to traverse the syntax tree and the peculiarities of the library.
After opening a couple of issues in the natspec-smells repository, a sudden and unexpected RiiR™ (Rewrite it in
Rust) urge came onto me. This was the perfect small-ish-scope project I was looking for to entertain my week-end!
This is how lintspec came to be. Besides the unoriginality of the name, I thought I had a very good shot at making a
tool that could be both much faster than the single-threaded, NodeJS-based natspec-smells, and also more ergonomic to
use.
Speed was an important factor because I wanted people to be able to use lintspec in git pre-commit hooks, where any
command running for more than a few hundreds of milliseconds really affects the developer experience.
What was initially a weekend project turned into 5 days of relatively intense development, until I felt I had most of the features I wanted in the tool. This didn’t include much unit and intergration testing, and a few days of bug-hunting shortly followed.
One of the important parts of the development was to create a parser for NatSpec comments, which was done with the help
of winnow. Since the lintspec crate is both a binary and a library, the parser can and
will be re-used for future projects!
Features
Below is a comparison table highlighting the features that were added in lintspec, which I felt were missing from
Wonderland’s implementation:
| Feature | lintspec | natspec-smells |
|---|---|---|
| Identify missing NatSpec | ✅ | ✅ |
| Identify duplicate NatSpec | ✅ | ✅ |
| Include files/folders | ✅ | ✅ |
| Exclude files/folders | ✅ | ✅ |
Enforce usage of @inheritdoc | ✅ | ✅ |
| Enforce NatSpec on constructors | ✅ | ✅ |
| Configure via config file | ✅ | ✅ |
| Configure via env variables | ✅ | ❌ |
| Respects gitignore files | ✅ | ❌ |
| Granular validation rules | ✅ | ❌ |
| Pretty output with code excerpt | ✅ | ❌ |
| JSON output | ✅ | ❌ |
| Output to file | ✅ | ❌ |
| Multithreaded | ✅ | ❌ |
| No pre-requisites (node/npm) | ✅ | ❌ |
Most notably, the ability to respect the patterns in .gitignore files, and the ability to output structured JSON were
at the top of my list. I also felt like the default output for the diagnostics (found problems) was a bit terse and
could benefit from some added flair. Since v0.4.0, the configuration is much more granular and allows to control the
emitted diagnostics for each source item type. Finally, having to install NodeJS and npm to run the tool always
seemed a bit tedious, especially since npm is not required to manage Solidity dependencies (thanks, soldeer!).
To produce pretty diagnostic messages, I used the amazing miette crate which gives
really good results with very little work.
Benchmark
Now, since performance has been identified as one goal for the tool, I can hear you from here: “how does it compare
to the competition?“. Feat not, reader, I have benchmarked the tool against natspec-smells after pretty much every development step. And the results are pretty good, dare I say!
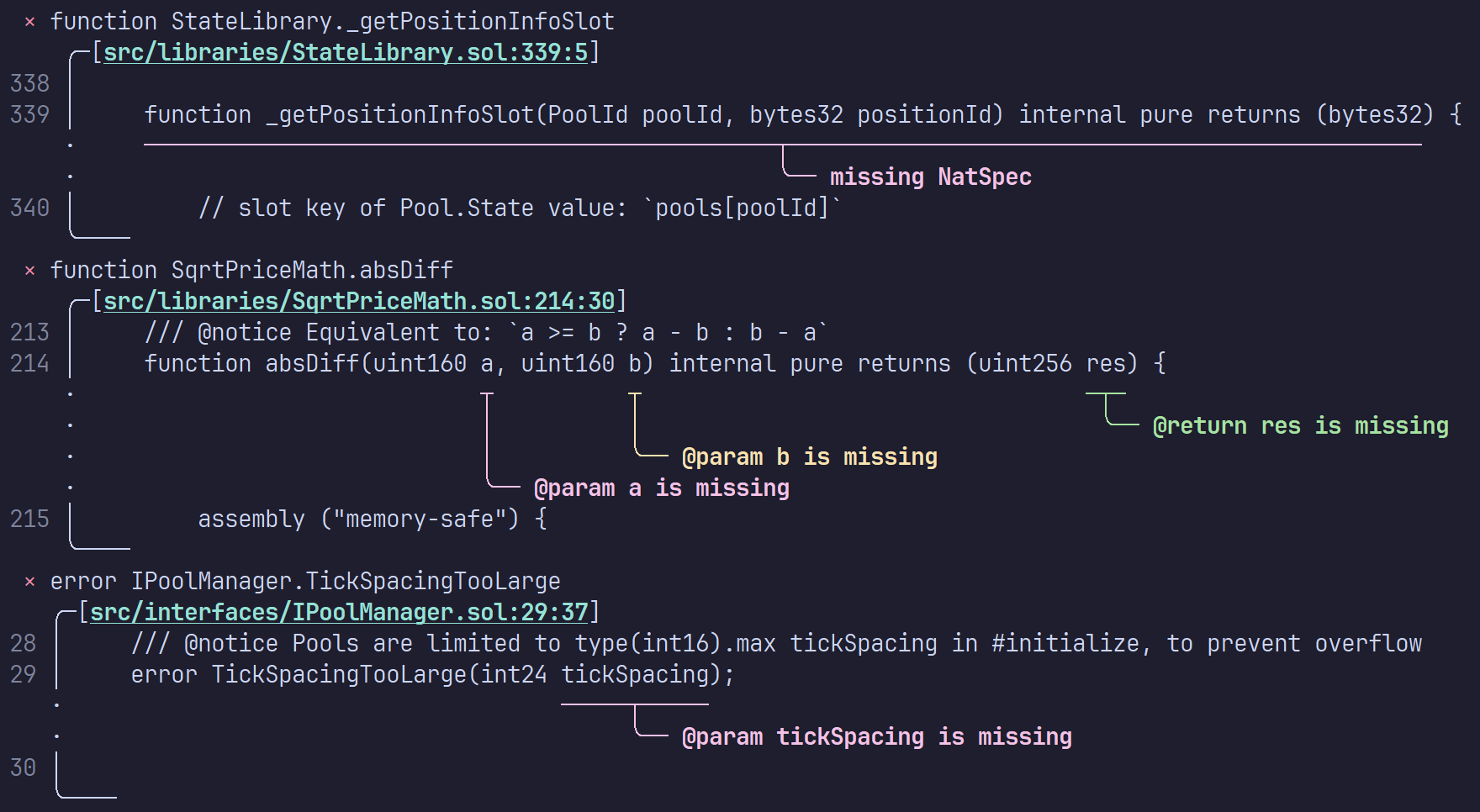
I used the Uniswap v4 codebase for this, because it includes (at the time of writing) 83 Solidity source files totaling about 6600 lines of code and comments, which is pretty representative of a large project where you’d be worried about the performance of a linter, and they don’t strictly enforce NatSpec for all items, which gives us a nice amount of diagnostics to output (487 of them!).
I set up lintspec’s output format to be as close as possible to what natspec-smells is doing, that is including
validation of struct members and using the compact text output format seen below:
# natspec-smells output
src/libraries/Pool.sol:83
Pool:State
@param slot0 is missing
@param feeGrowthGlobal0X128 is missing
@param feeGrowthGlobal1X128 is missing
@param liquidity is missing
@param ticks is missing
@param tickBitmap is missing
@param positions is missing
# lintspec output
src/libraries/Pool.sol:78:1
struct Pool.State
@param slot0 is missing
@param feeGrowthGlobal0X128 is missing
@param feeGrowthGlobal1X128 is missing
@param liquidity is missing
@param ticks is missing
@param tickBitmap is missing
@param positions is missingI used the excellent hyperfine tool for comparing both commands. Granted the
machine I’m on for this benchmark has 16 cores (AMD Ryzen 9 7950X), which greatly benefits from the multithreaded
capabilities of lintspec, the verdict is clear:
Benchmark 1: npx @defi-wonderland/natspec-smells --include "src/**/*.sol"
Time (mean ± σ): 13.034 s ± 0.138 s [User: 13.349 s, System: 0.560 s]
Range (min … max): 12.810 s … 13.291 s 10 runs
Benchmark 2: lintspec src --compact --param-required struct
Time (mean ± σ): 62.9 ms ± 2.4 ms [User: 261.9 ms, System: 69.6 ms]
Range (min … max): 55.1 ms … 66.5 ms 47 runs
Summary
lintspec src --compact --param-required struct ran
207.34 ± 8.28 times faster than npx @defi-wonderland/natspec-smells --include "src/**/*.sol"Run It in CI
lintspec comes with a built-in Github Action that you can use in your workflows. Here’s an example of how you would
use it. Of course, it can be customized with parameters, check out the GitHub repository to learn more:
name: Lintspec
on:
pull_request:
jobs:
lintspec:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: beeb/lintspec@main
Thanks to the JSON output generated by the tool, it’s easy to extract information about the found problems with
utilities like jq and make your own if you don’t use Github Actions.
The CLI exits with code 1 if some diagnostics were found, and 0 if everything is good. This makes it even easier to
fail a workflow run if problems are found. Note that diagnostics are by default emitted in stderr and so you might
need to redirect output to stdout for piping into jq. Here are a couple of queries you might be interested in:
lintspec src --json 2>&1 | jq 'length' # number of files with problemslintspec src --json 2>&1 | jq '[.[].items[].diags | length] | add // 0' # total number of problemsWhat’s Next
Although the test suite is now pretty extensive, I’m sure there are some bugs I didn’t find yet. I would be extremely greateful if you could consider using the tool and letting me know how it goes! Please do open an issue on GitHub if you have suggestions or experience problems.
Thanks for reading all the way to the end, and talk soon!
Updated 2025-03-14
Updated usage section to v0.4, updated features comparison table, and benchmark results.